2025-07-03 15:50

![]()

你是不是也感覺——AI 越來越像人了?
它能理解你的問題、給你建議,甚至還能陪你聊天談心;
大模型(LLM)不僅在說話,簡直是在思考。
但你有沒有想過:這些模型為什么像人類一樣“思考”?
是因為數據多了?參數大了?算法復雜了?LLM背后的邏輯如果用一句話總結,應該是——LLM 背后其實是利用了一個 18 世紀的“人類思考公式”:貝葉斯定理(Bayes’ Theorem)。
貝葉斯定理是以18世紀英國數學家和神父托馬斯·貝葉斯(Thomas Bayes)的名字命名的,是一種用于更新我們對某個事件發生概率的方法。通俗地理解,你可以將其比作一種“修正”或“調整”我們的信念。
假設你有一個關于某件事情發生概率的初始猜測,這個猜測可能是主觀的、基于經驗的、或者是先驗知識。然后,當你獲得新的信息或證據時,你可以使用貝葉斯定理來重新評估你的初始猜測,得到一個更準確的估計。
每次我們面對不確定的事物做出決策時——一直以來我們都是這樣做的——都可以利用貝葉斯定理來判斷該決策在多大程度上算是個好決策。
事實上,無論是怎樣的決策過程,無論你為了實現某個目標對世界產生了多大的影響,無論你掌握的信息多么有限,無論你是正在尋找高濃度葡萄糖環境的細菌,是正在利用復制行為傳播遺傳信息的基因,還是正在努力實現經濟增長的政府,只要你想把事情干好,你就離不開貝葉斯定理。
AI(人工智能)本質上也是貝葉斯定理的一個具體應用。
從最基本的層面來說,AI 所做的事情就是“預測”。一個可以分辨貓狗圖像的 AI 應用,本質上就是在根據過往的訓練數據和當前的圖像信息去“預測”人類對圖片的判斷。DALL-E 2、GPT-4、Midjourney 等各種優秀的 AI 應用,正在以令人應接不暇的速度一次次沖擊人們的認知。
不過,這些和你談笑風生、為你生成高質量圖像的 AI,本質上也是在做預測,只不過它們預測的是人類作家、人類藝術家面對這些提示詞時會如何作答。這些預測行為的基礎都是貝葉斯定理。
AI 本質上是在不確定的情況下做出抉擇。谷歌的密碼學家保羅·克勞利告訴我:“如果你懂貝葉斯理論,你就會發現 AI 在最基本的層面上用到了大量貝葉斯思想。”
現代的那些 AI 神經網絡存在大量節點,這些節點就像大腦中的神經元一樣。AI 會在學習過程中為不同的節點鏈接賦予不同的權重,從而加強或削弱各節點之間的關聯程度。
保羅·克勞利表示:“AI 內部有一套評分機制,權重體系越復雜,它的得分就越低,反之就越高。如此一來,我們就能迫使它盡量采用更簡單的假說,而不是更復雜的假說,這看上去完全就是貝葉斯思想;其先驗概率就是建立在奧卡姆剃刀原則之上的。進行完整的貝葉斯計算需要耗費大量算力,所以現代這些 AI會盡量使用算力需求較低但性能表現并不會遜色多少的簡化算法。”
不管怎么說,貝葉斯思想都是 AI 的基本原理之一。“大多數現代AI 系統的基本思想都是貝葉斯定理,因為它們關心的都是不確定情況下的推理方法”。
事實上,有一種 AI 算法就叫“貝葉斯機器學習”,它的整個構架都在模仿貝葉斯定理。
假定現在有一個非常簡單的 AI,它的任務是識別老鼠、狗、獅子的圖片。如果是十幾年前,這種 AI 足以令人感到震撼,但放到今天來看,它簡直太普通了(其實就在 2017 年,我為第一本書的創作而四處走訪時,AI 能夠將貓狗區分開來還是一件非常新奇的事。至于現在,你只需要掏出自己的智能手機就可以做到這一點,它甚至可以在幾分之一秒內將照片庫中的狗狗、嬰兒、海灘等類別的照片全部給你篩選出來)。
理論上來說,它的工作方式是這樣的:
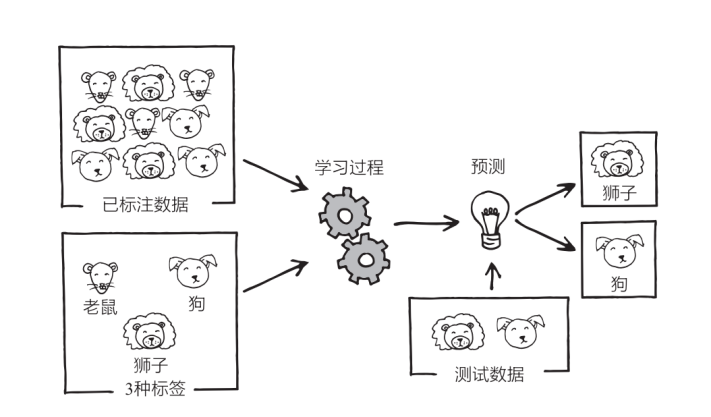
你“喂”給 AI 幾百萬或幾千萬張分別標好“老鼠”“狗”“獅子”的圖片,讓它利用這些“已標注數據”進行訓練,然后它就會以某種方式反復學習數據。學習完成之后,你需要再拿幾張它沒見過的圖片(“測試數據”)進行測試,此時它會根據自己的學習經驗對這些測試圖片做出最佳猜測,并給這些圖片分別標上“老鼠”“狗“獅子”的標簽。
AI 的這種學習方式就是所謂的“監督學習”。它所干的事情,就是預測“那些喂給自己學習數據的人類”會給新圖片標上什么標簽。”
當然,我們也可以用貝葉斯思想去解釋這一過程,二者幾乎是一樣的:在看到某張圖片之前,這個 AI 可能會主觀地認為這是一只獅子的先驗概率為 1/3,即 p ≈0.33。看到圖片之后,也就是得到新信息之后,它會將這一概率更新為 p=0.99,或其他什么數字。先驗概率、似然比、后驗概率。
我們可以更具體一些。現在我們將情況進一步簡化,把上面的例子看成一張圖,圖上面有一堆數據點。此時 AI 的任務是分析圖像,然后找到一條能夠穿越這些數據點的最佳擬合直線。事實上,我們根本不需要強大的 AI 來干這種事,因為這只是線性回歸而已,高爾頓那個年代的統計學家就可以輕松解決這一問題。不過原理是一樣的。
假定這些數據點表示的是人們的鞋碼與身高——你隨機抽取了一大群人,測量了它們的身高和鞋碼。圖上 X 軸表示的是鞋碼,Y軸表示的是身高。通常來說,這些數據點會分布在左下至右上的區域附近。
AI 的任務就是找出這些數據點的最佳擬合直線。當然,你也可以憑感覺來畫,但我們最好采用一個已經相當成熟的方法,即最小二乘法。在圖上畫一條直線,然后測量每個數據點和這條直線的垂直距離,這一距離就是“誤差”。將每個點的距離,也就是誤差,取平方值(平方是為了讓所有數都是正數),然后將所有平方值加總,得到平方和。
我們的目標就是找到能讓平方和達到最小值的直線,即每個數據點的平均距離最短的直線。
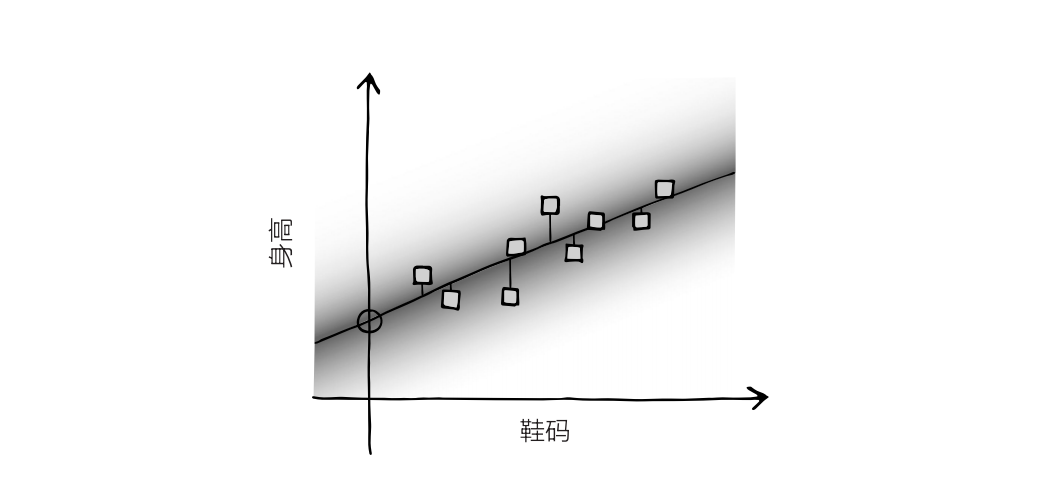
這些數據點可以視為 AI 的訓練數據,而這一過程也用到了貝葉斯思想。首先,圖上分布著一條直線,代表著寬泛的先驗概率。然后我們在圖上加入了數據點——代表數據。之后這條直線會根據數據而移動,得出后驗分布。最后這條直線又會成為下一批數據的先驗分布。
假如你現在知道一個人的鞋碼是 11 號,想用它預測這個人的身高,那它就會用最小二乘法畫出一條最佳擬合直線,然后讀取橫坐標 11 所對應的縱坐標,這個縱坐標就是 AI 對身高的最佳猜測。它有多大把握,取決于訓練數據有多少,以及訓練數據有多分散。數據越分散,把握就越小。
當然,這只是 AI 最基本的原理,實際上它們要比這復雜得多,涉及的參數也不會只有鞋碼、身高,而是成千上萬個,但基本思路是一樣的。所有 AI 都需要大量的訓練數據,然后根據某些參數去預測另一些參數的值。
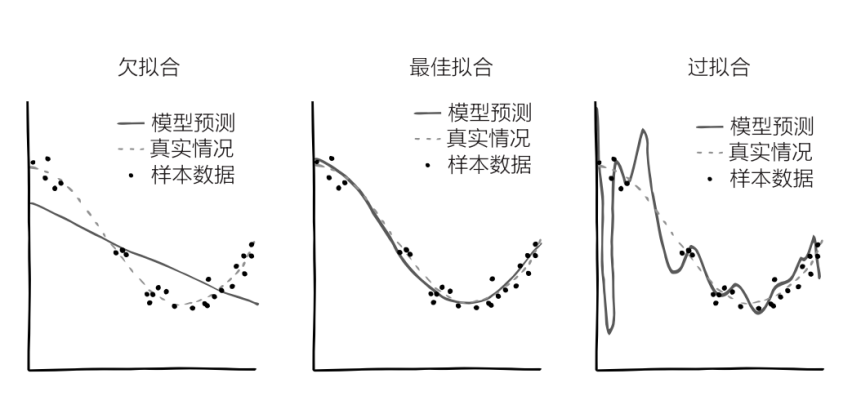
目前為止,我們一直假設這條線是直線,其實真實情況下它更可能是曲線。如果 Y 軸表示的是“新冠病毒感染者的全球病例數”,X 軸表示的是“時間”,起始時間是 2019 年 11 月,那么最符合實際情況的應當是條指數曲線,因為病例數量每隔幾天就會翻一番。有的時候,最佳擬合曲線會長得像英文字母 S 或 J,也可能是一條正弦曲線,或其他什么形狀的曲線。當然你可以讓 AI 一直依照直線去模擬,但大多數情況下這并不是一個好的選擇:這會導致這條線“欠擬合”。
同樣,你也可以讓 AI 變得極為復雜,這樣它就會畫出一條七扭八歪的、完美穿過每一個數據點的曲線,此時誤差的平方和等于0。雖然看起來很美好,但這很可能無法反映出數據背后的真實情況。出現新數據時,這條七扭八歪的曲線很可能距離新的數據點相去甚遠,因為這條線已經變得“過擬合”了。
由此可見,問題的關鍵在于 AI 應當在多大程度上去擬合曲線,這種程度就是自由度。自由度有點像前兩節中的“超參數”——除了最佳擬合曲線這個問題,我們還應當關心一個更高層次的問題,即這條曲線應當有多“扭曲”。AI 對這些參數的先驗判斷就是它的超先驗。通常情況下,在其他情況都相同的情況下,AI 會在兩條線中選取更簡單的那條。還記得嗎?在講奧卡姆剃刀原則的時候我們曾提到,我們要權衡假說的簡單程度和符合程度,AI 也需要做這種權衡。
醫用 AI 在試圖分辨癌癥的掃描結果時,ChatGPT 在試圖仿照《英王欽定本圣經》中描寫的一個男人努力取出電視機里的三明治的情節時,都用到了貝葉斯思想。它們都在根據訓練數據生成先驗概率,然后用這些先驗概率預測未來的數據。
雖然貝葉斯定理不是萬物理論,但實際上也差不多了。一旦你開始站在貝葉斯定理的視角去看待問題,你就會發現貝葉斯定理真的是無處不在。
 京公網安備 11010802028547號
京公網安備 11010802028547號
 購物車
購物車






